第2章 第4节 预训练(一)-本质
第2章 第4节 预训练(一)-本质
阅读指南
前面几节讨论了ChatGPT的参数规模、文字接龙游戏、语言建模思想和Embedding词向量。但最核心的问题还没有回答:那1750亿个参数,到底是怎么"训练"出来的?本节将揭示预训练的核心机制。
4.1 什么是预训练?
预训练就是让模型在海量文本上学习语言规律,像人类"读万卷书"一样积累知识。
它的核心思想很简单:给模型看大量文本,让它不断预测下一个词,然后根据正确答案调整参数。经过数十亿次的调整,模型就"记住"了语言的规律。
这个过程分为4个步骤:收集数据、定义任务、训练模型、训练完成。让我们详细看看每一步。
4.2 预训练的4个步骤
第1步:收集海量数据
GPT-3的训练数据约3000亿个词,相当于600万本书。这些数据来自互联网的各个角落:
数据源 占比 说明
────────────────────────────────────────────────────
Common Crawl(网页) 60% 互联网网页爬取
WebText2(精选网页) 22% Reddit高赞链接
Books(书籍) 16% 精选书籍
Wikipedia(维基百科) 3% 英文维基百科条目
Note
数据来源基于OpenAI论文公开的比例,详见《Language Models are Few-Shot Learners》,OpenAI,2020。
第2步:定义训练任务
训练数据多是连续的文本,那么如何从一句完整的话变成训练任务?
假设原始文本:
"人工智能是计算机科学的一个分支"
Token化
ChatGPT不能直接处理文字,必须先把文字切成Token:
原始文本: "人工智能是计算机科学的一个分支"
↓ Token化(切分)
["人工智能", "是", "计算机科学", "的", "一个", "分支"]
↑ ↑ ↑ ↑ ↑ ↑
Token1 Token2 Token3 Token4 Token5 Token6
总共 6 个 Token
所以:
- 从互联网爬取的是原始文本(字符串)
- 经过Token化后变成Token序列(数字序列)
- 训练时使用的是Token,不是原始文字
自动切分成训练样本
计算机把这些Token切成很多个"填空题",答案就在原文里:
原始文本:"人工智能是计算机科学的一个分支"
↓ 自动切分并配对
训练样本1:
输入:"人工智能____"
答案:"是" ← 从原文取下一个Token
训练样本2:
输入:"人工智能是____"
答案:"计算机科学"
训练样本3:
输入:"人工智能是计算机科学____"
答案:"的"
训练样本4:
输入:"人工智能是计算机科学的____"
答案:"一个"
训练样本5:
输入:"人工智能是计算机科学的一个____"
答案:"分支"
↑ T1(人工智能)前面没有Token,不能作为预测目标,所以6个Token只生成5个训练样本
Caution
预训练是从左到右预测的,只能根据前面的词预测下一个词,不能"挖空"中间的词。这就是为什么叫"语言模型"——它模拟人类从左往右阅读和写作的过程。
即:不会出现"人工智能是___计算机科学的一个分支"这样的训练数据。
现在我们有了无数个训练样本,每个样本都有输入和答案。接下来的问题是:模型如何利用这些数据学习?
第3步:训练模型——不断预测、对比、调整
训练的核心机制很简单:让模型做预测,然后把预测结果与正确答案对比,根据差距调整参数。
单次训练过程:
1. 给模型看输入:"人工智能是计算机科学的一个____"
2. 模型预测:"领域" (初期是随机猜的)
3. 对比答案:"分支" (从原文匹配到的)
4. 计算错误:预测"领域" ≠ 答案"分支" → 错了!
5. 调整参数:修正1750亿个参数,让模型下次更可能输出"分支"
但这只是一次训练!真正的训练是一个循环往复的过程:
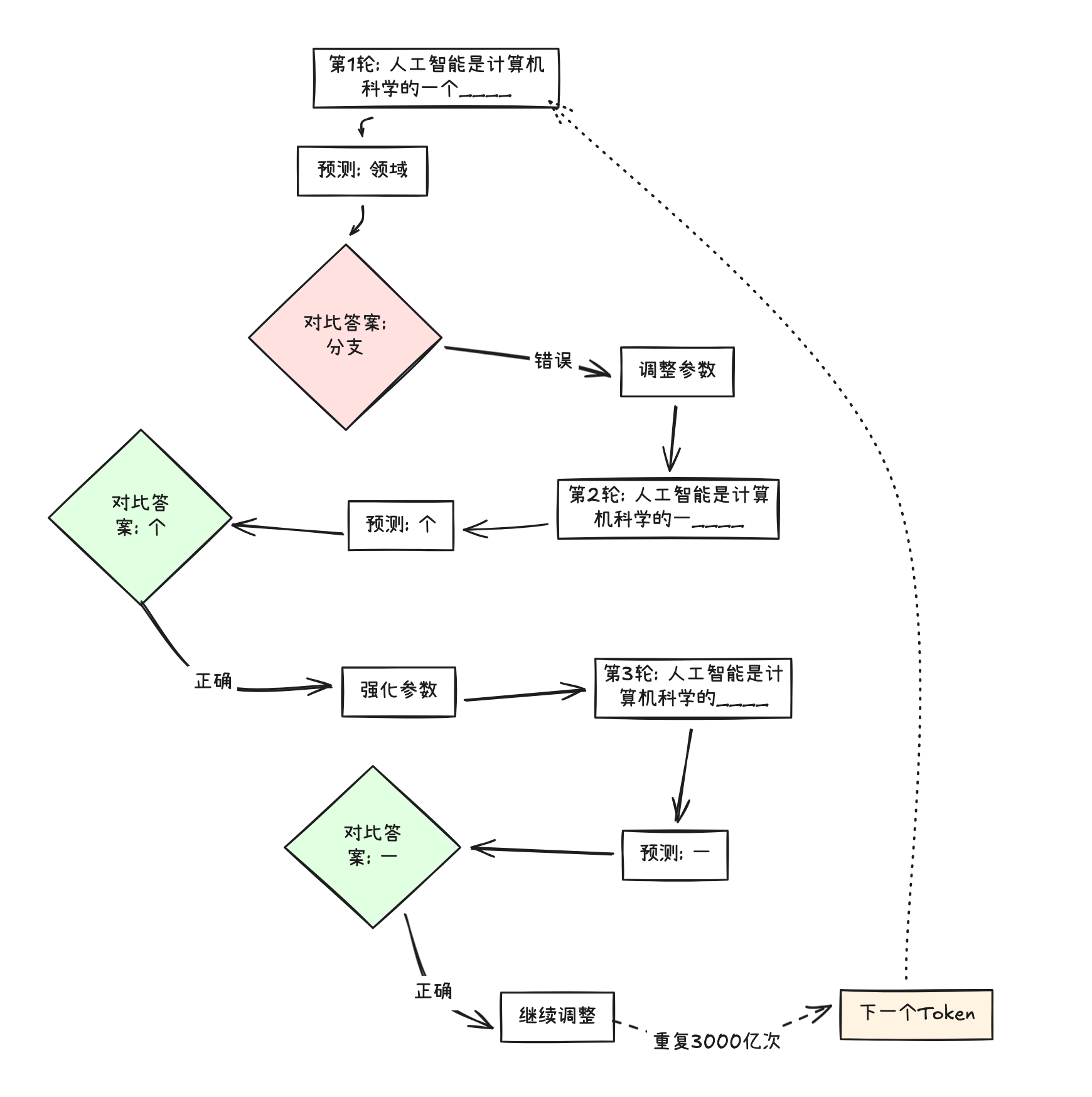
关键点:
- 一句话"人工智能是计算机科学的一个分支"切成6个Token,能生成5个训练样本(每个Token位置一个)
- 3000亿Token ≈ 3000亿次调整 ≈ 3000亿次学习机会
- 每次调整,1750亿个参数都会轻微改变
- 经过3000亿次循环,模型逐渐"学会"了语言规律
第4步:训练完成
1750亿个参数调整完毕,模型"记住"了语言的规律,就像一个"读过"3000亿词的语言专家。
4.3 监督学习 vs 自监督学习
现在来解释一个至关重要的概念,它是预训练能够规模化的关键。
传统的监督学习:需要人工标注
用情感分析作为例子(这已经是监督学习中最简单、成本最低的任务了):
任务:情感分析(分类任务)
数据:
"这部电影真好看!" → 标签:正面 ← 需要人工判断并标注
"浪费时间,很无聊" → 标签:负面 ← 需要人工判断并标注
"还准备看第二遍!" → 标签:正面 ← 需要人工判断并标注
...
标注10万条数据,耗时数月,可能花费成本数十万美元,然后只能训练一个做情感分析的模型。
这里有个常见误区:很多同学认为监督学习的流程是机器回答问题,然后人类标注员告诉机器是否正确。但其实更常见的方式是人类标注员预先标注好答案。
举例来说:
- 情感分析:标注员看到"这部电影真好看" → 判断是正面情感 → 打上"正面"标签
- 机器翻译:标注员看到"I love this book" → 翻译为"我喜欢这本书" → 形成一对训练数据
收集到足够多的标注数据后,才开始训练模型。所以监督学习的训练数据都是成对的:文本-答案。
看似合理,但有很大问题:
- 标注成本高昂,无法规模化
每条数据都需要人工判断,成本极高。
- 任务单一化
对于同一个例句,可能有不同角度的用途:情感分析(正负)、翻译、摘要。但往往一批标注员只做某一个方向的标注,没有将训练数据的收益最大化。
- 数据量受限
用于训练模型的数据量极其庞大,要想尽可能处理这些信息,只靠人工根本不可能。
而且,情感分析属于分类任务,已经是监督学习中相对最简单的类型(只需选择预定义的标签)。如果是更复杂的任务,成本会更高:
- 机器翻译:需要专业翻译人员,标注一段文本可能需要1分钟左右
- 问答系统:需要理解问题并撰写答案,标注一条问答对可能需要1到5分钟
- 文本摘要:需要阅读长文并提炼核心,标注一条摘要可能需要10-20分钟
监督学习的标注成本,会随着任务复杂度指数级增长。
预训练的自监督学习:完全不同
任务:预测下一个Token(填空任务)
数据:
原始文本:"人工智能是计算机科学的一个分支"
自动生成训练样本(每个位置都有一道填空题):
填空题1:
输入:"人工智能____"
答案:"是" ← 不需要人工标注,原文里就有!
填空题2:
输入:"人工智能是____"
答案:"计算机科学"
填空题3:
输入:"人工智能是计算机科学____"
答案:"的"
填空题4:
输入:"人工智能是计算机科学的____"
答案:"一个"
填空题5:
输入:"人工智能是计算机科学的一个____"
答案:"分支" ← 每个位置自动生成一道题
自监督学习的优势很明显:
答案在原文里
下一个Token就是标签,不需要人工判断。
样本自动生成
一句话能生成无数个训练样本,把原文切开就行。
零标注成本
从互联网爬取文本即可,不需要人工打标签。
规模爆炸式增长
监督学习可能只能标注10万条,但预训练可以到3000亿个Token。
这就是预训练能够改变AI的根本原因。
4.4 下一节预告
现在知道了预训练的4个步骤和自监督学习的优势。但训练这样一个模型需要多少资源?为什么只有少数科技巨头能玩这个游戏?
下一节将看到预训练的惊人代价,以及数据质量的重要性。
4.5 ■ 学点英语
| 中文 | English | 音标 | 说明 |
|---|---|---|---|
| 预训练 | Pre-training | /priː ˈtreɪnɪŋ/ | 在海量无标注文本上训练语言模型学习通用语言能力的过程 |
| 监督学习 | Supervised Learning | /ˌsuːpərvaɪzd ˈlɜːnɪŋ/ | 使用人工标注的数据训练模型做特定任务的方法 |
| 自监督学习 | Self-Supervised Learning | /self ˈsuːpərvaɪzd ˈlɜːnɪŋ/ | 从数据本身自动生成标签(如下一个Token预测)的训练方式 |
| 下一Token预测 | Next-Token Prediction | /nekst ˈtoʊkən prɪˈdɪkʃən/ | 语言模型根据已有Token序列预测下一个Token的核心训练任务 |
| 训练样本 | Training Sample | /ˈtreɪnɪŋ ˈsæmpl/ | 模型训练中用到的输入-输出对(输入文本+要预测的下一个Token) |
| 收敛 | Convergence | /kənˈvɜːrdʒəns/ | 模型训练中参数接近最优解、损失不再显著下降的状态 |